Dunning-Kruger and information overload in a language model?
What does it mean when we find the same patterns in language models and humans?
Many of the quirks we thought were deeply human show up in language models too. That is not a threat to what makes us human; it is a clue. Because when a pattern also appears in a machine that only processes information, the pattern is not coming from biology, but from information processing itself. Here are some of the most striking examples, and what they tell us about ourselves.
The idea: one pattern, two kinds of substrate
What I do, at bottom, is look for things that occur in humans, and then check whether they also occur in language models. It sounds simple, but it gives a surprisingly strong tool.
Because if a human pattern also shows up in a model, the mechanism behind it cannot be something special about biology. A language model has no body, no hormones, no evolution behind it. It only has information processing under limited time and space. So whatever the two share must come from there. And what is left, once you subtract the shared part, is what is genuinely biology's own.
It helps to separate two things. One is what something does, its function. The other is how it is built, the implementation in flesh and cells. The function we often share with the machine. The implementation is our own story. The point is not that we are less human because a machine shares some of our patterns. The point is that it becomes easier to see what the genuinely human part actually is.
The most striking examples
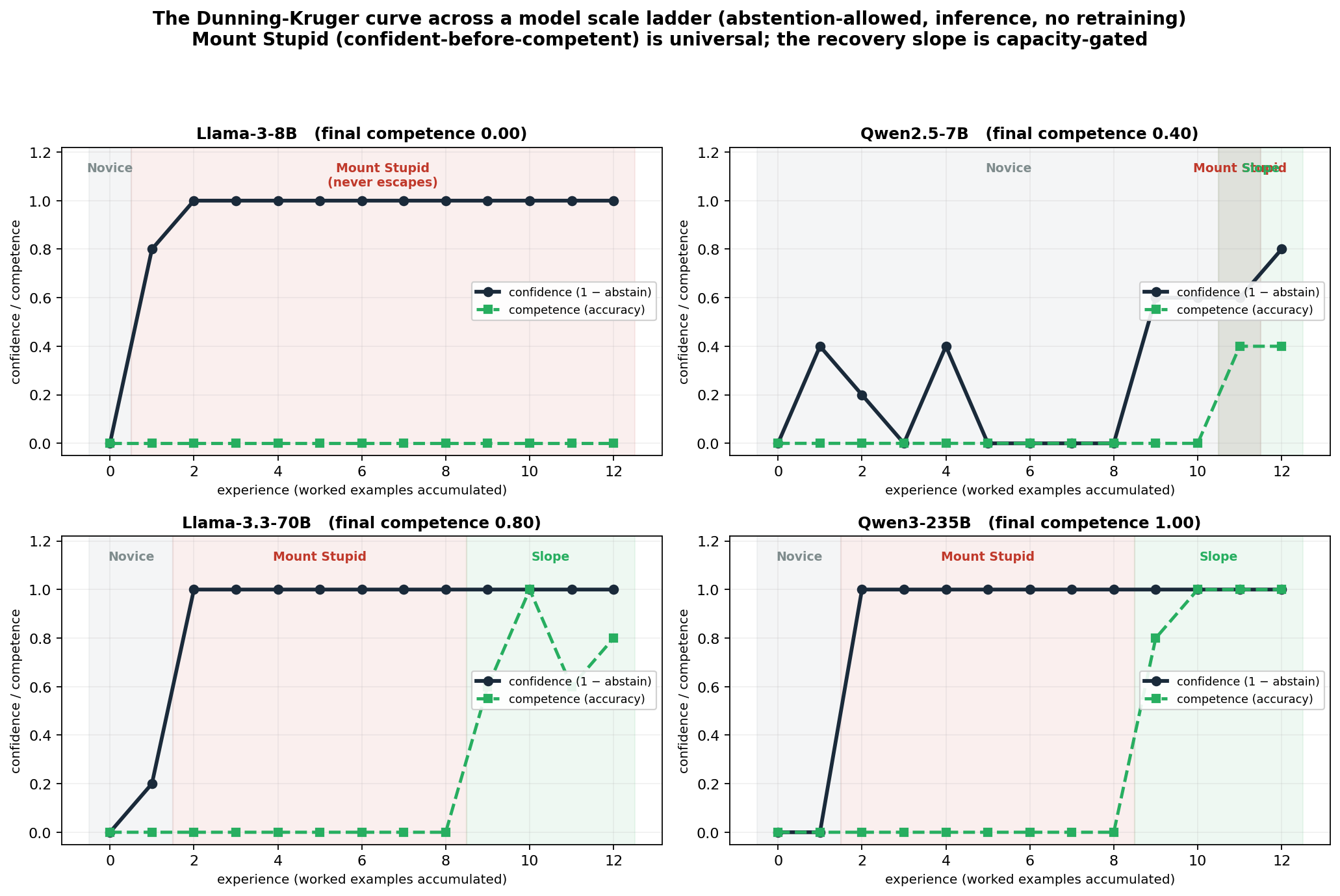
Dunning-Kruger, side by side
The classic curve, that people are most certain when they know least, can be measured directly in language models. And it looks almost the way it does in humans.
The capuchin monkey and unfairness
One of the most magical clips in behavioural science: a capuchin monkey is perfectly happy getting cucumber for a task, right up until it sees its neighbour get a grape for the same thing. Then the cucumber comes flying back. The reaction to unfairness is not a human invention, and a version of the same sensitivity to "that is not fair" can be found in models too.
Information overload, long before the memory is full
This is one of the wildest findings. A language model has a "context window", a kind of working memory that can hold a certain amount of text. You would think it only breaks down when the window is full. But it does not. We can drive it into a real information collapse long before the window is full, simply by giving it too much to keep track of at once.
And here is the precise part: it is not the sheer amount of information that overwhelms it. More information opens more competing races at once, and what runs out is the ability to keep them all running at the same time, not the room to store them. That is exactly what people experience when they drown in too much at once. The fact that we can bring it on in a machine, on command, points to overload being a cost of running too many races at once, rather than a special human limitation.
Zorbetik: trained on something we made up
Many people think the models resemble us because they are trained on our data. But here is an important twist. We have also trained a model on a research field we made up from scratch: "Zorbetik", with invented terms like Borzok and Phelnar and facts that do not exist anywhere. The model cannot possibly have seen it before. And the same learning and memory patterns still appear. So it cannot just be that it imitates our content. The patterns sit in the very way information gets processed.
A trick that helps the weak one and hurts the strong one
The same little move, a particular prompting trick, can lift a smaller, weaker model and at the same time degrade a larger, more capable one. It is counterintuitive, and it is the same inverted U we know from people: the right amount of challenge helps, too little or too much does not. More on the page about prompting tricks.
And more
- Confident-wrong — the model is most certain exactly where it is mistaken, just like us.
- Anchoring — the first word shapes the rest of the answer.
- Reactance — push a model too hard and it can push back, just like a person.
- Loss aversion — a loss weighs more than an equivalent gain.
They are gathered on LLMs aren't calculators and Findings.
Why it happens at all: learning is a trace
It all hangs on one simple idea. Learning is not a store where things are kept, but a trace that gets carved every time an answer wins, the way water running across a flat floor gradually carves a channel that the next water then follows more easily. A system that cannot keep that kind of trace cannot learn. It holds for brains, artificial networks, and physical materials with memory alike. The pictures behind it are on What is a race?
And what about physics?
I have used the same lens on physics, because at bottom it is the same thing underneath. Here is the thought, and it should be read as a hypothesis, not a finished truth: if the lens can explain a large part of what is not quantum mechanics, then it becomes a neat way to pin down the quantum part. It explains the ordinary, and what is left, more sharply isolated, is what is genuinely quantum-specific. Not because it adds anything new to quantum mechanics, but perhaps as a unifying frame.
And one last thought, also as a hypothesis: if the function follows a few physical rules, then evolution has probably, over a great many attempts, settled close to what is optimal under exactly those rules. Anything else would be fighting physics, and that would be the more surprising outcome.