Dunning-Kruger og information overload i en sprogmodel?
Hvad betyder det, når vi finder de samme mønstre i sprogmodeller og mennesker?
Mange af de særheder, vi troede var dybt menneskelige, dukker også op i sprogmodeller. Det er ikke en trussel mod det menneskelige; det er et spor. For når et mønster også viser sig i en maskine, der kun behandler information, så stammer mønstret ikke fra biologien, men fra selve informationsbehandlingen. Her er nogle af de mest slående eksempler, og hvad de fortæller os om os selv.
Idéen: ét mønster, to slags substrat
Det jeg i bund og grund gør, er at lede efter ting der findes i mennesker, og så se efter, om de også findes i sprogmodeller. Det lyder enkelt, men det giver et overraskende stærkt redskab.
For hvis et menneskeligt mønster også dukker op i en model, så kan mekanismen bag det ikke være noget særligt ved biologien. En sprogmodel har ingen krop, ingen hormoner, ingen evolution bag sig. Den har kun informationsbehandling under begrænset tid og plads. Så det de to deler, må stamme derfra. Og det der bliver tilbage, når man trækker det fælles fra, er så det der faktisk er biologiens eget.
Det er værd at skille to ting ad. Den ene er hvad noget gør, funktionen. Den anden er hvordan det er bygget, implementeringen i kød og celler. Funktionen deler vi ofte med maskinen. Implementeringen er vores egen historie. Pointen er ikke at vi er mindre menneskelige af at en maskine deler nogle af vores mønstre. Pointen er at vi lettere kan få øje på, hvad der så er det særligt menneskelige.
De mest slående eksempler
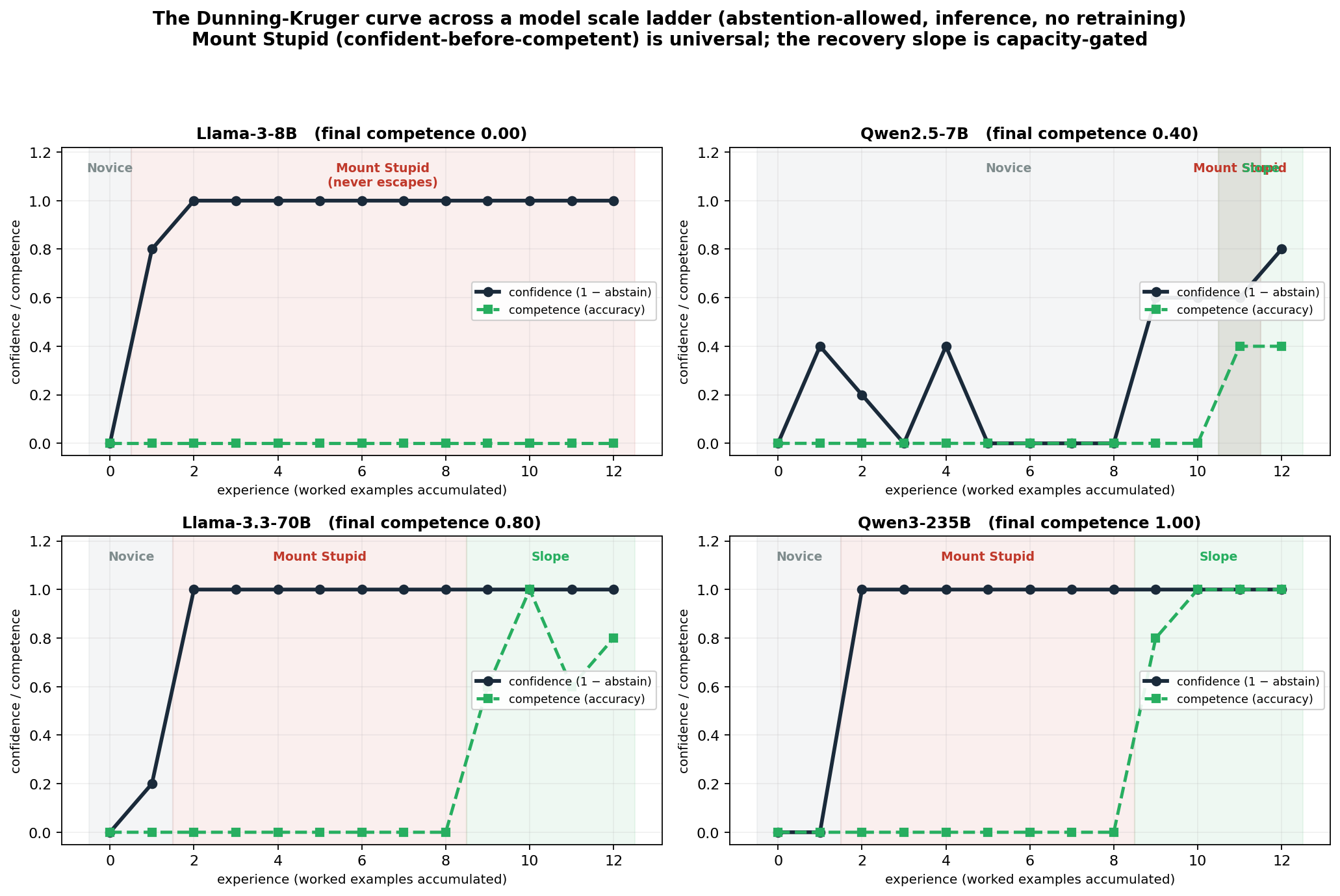
Dunning-Kruger, side om side
Den klassiske kurve, at man er mest skråsikker, når man ved mindst, kan vi måle direkte i sprogmodeller. Og den ser ud næsten som hos mennesker.
Kapucineraben og uligheden
Et af de mest magiske klip i adfærdsforskningen: en kapucineraber er fuldt tilfreds med at få agurk for en opgave, lige indtil den ser naboen få en drue for det samme. Så ryger agurken retur. Reaktionen på uretfærdighed er ikke en menneskelig opfindelse, og en version af den samme følsomhed for "det er ikke fair" kan vi også genfinde i modeller.
Information overload, længe før hukommelsen er fuld
Det her er et af de vildeste fund. En sprogmodel har et "kontekst-vindue", en slags arbejdshukommelse, der kan rumme en bestemt mængde tekst. Man skulle tro, at den først gik ned, når vinduet var fyldt op. Men det gør den ikke. Vi kan presse den ud i et regulært informationskollaps længe før vinduet er fyldt, bare ved at give den for meget at holde styr på på én gang.
Og her er det præcise: det er ikke mængden af information i sig selv, der overvælder den. Mere information åbner flere konkurrerende races på én gang, og det der slipper op, er evnen til at holde dem alle kørende samtidig, ikke pladsen til at gemme dem. Det er præcis det, mennesker oplever, når de drukner i for meget på én gang. At vi kan fremkalde det i en maskine, på kommando, peger på at overbelastning er en omkostning ved at køre for mange races på én gang, snarere end en særlig menneskelig begrænsning.
Zorbetik: trænet på noget vi selv har fundet på
Mange tror, at modellerne ligner os, fordi de er trænet på vores data. Men her er en vigtig drejning. Vi har også trænet en model på et forskningsfelt, vi har fundet på fra bunden: "Zorbetik", med opdigtede begreber som Borzok og Phelnar og fakta, der ikke findes nogen steder. Modellen kan umuligt have set det før. Og alligevel dukker de samme lærings- og hukommelsesmønstre op. Så det kan ikke bare være, at den efterligner vores indhold. Mønstrene sidder i selve måden, information bliver behandlet på.
Et trick der hjælper den svage og skader den stærke
Det samme lille kneb, et bestemt prompt-trick, kan løfte en mindre, svagere model og samtidig forringe en større, mere kapabel én. Det er kontraintuitivt, og det er den samme omvendte U-form vi kender fra mennesker: den rette mængde udfordring hjælper, for lidt eller for meget gør ikke. Mere om det på siden om prompt-tricks.
Og flere
- Selvsikker-forkert — modellen er mest skråsikker præcis dér, hvor den tager fejl, ligesom os.
- Anchoring — det første ord former resten af svaret.
- Reactance — pres en model for hårdt, og den kan slå tilbage, ligesom et menneske.
- Tabsaversion — et tab vejer tungere end en tilsvarende gevinst.
De er samlet på Sprogmodeller er ikke regnemaskiner og Opdagelser.
Hvorfor det overhovedet sker: læring er et spor
Det hele hænger på en enkel idé. Læring er ikke et lager, hvor ting bliver gemt, men et spor, der bliver gravet, hver gang et svar vinder, sådan som vand der løber hen over et fladt gulv, gradvist graver en rende, som det næste vand så lettere følger. Et system, der ikke kan bevare den slags spor, kan ikke lære. Det gælder lige meget for hjerner, kunstige netværk og fysiske materialer med hukommelse. Billederne bag ligger på Hvad er et race?
Og hvad med fysikken?
Jeg har brugt den samme linse på fysikken, for det er i bund og grund det samme nedenunder. Her er tanken, og den skal læses som en hypotese, ikke en færdig sandhed: hvis rammen kan forklare en stor del af det, der ikke er kvantemekanik, så bliver den en pæn måde at indkredse det kvantemekaniske på. Den forklarer det almindelige, og så står tilbage, skarpere isoleret, hvad der faktisk er det kvante-særlige. Ikke fordi den bidrager med noget nyt til kvantemekanikken, men måske som en samlende ramme.
Og en sidste tanke, også som hypotese: hvis funktionen følger nogle få fysiske regler, så har evolutionen formentlig over rigtig mange forsøg lagt sig tæt op ad det, der er optimalt under netop de regler. Alt andet ville være at kæmpe imod fysikken, og det ville være det mere overraskende udfald.