Why "knows little, believes a lot"
It shows up in language models too, and that reveals what it really is
The Dunning-Kruger effect shows up in a language model such as ChatGPT too. And it is stranger than it sounds. A machine is not vain. It does not kid itself that it is cleverer than it is. Yet it still grows most certain exactly when it knows least. So when the effect shows up there as well, it cannot be about a fragile human ego. It must be something more basic. And because we can look straight inside the model, we can now see exactly why it happens.
A teacher with a secret grading system
Imagine a teacher with a secret grading system. The rule is simple: your grade is your number on the class list. Student no. 3 gets 3, student no. 7 gets 7. But there is a hidden exception: every student whose number is divisible by 5 (5, 10, 15, 20, and so on) gets 100 added. So student no. 10 does not get 10, but 110.
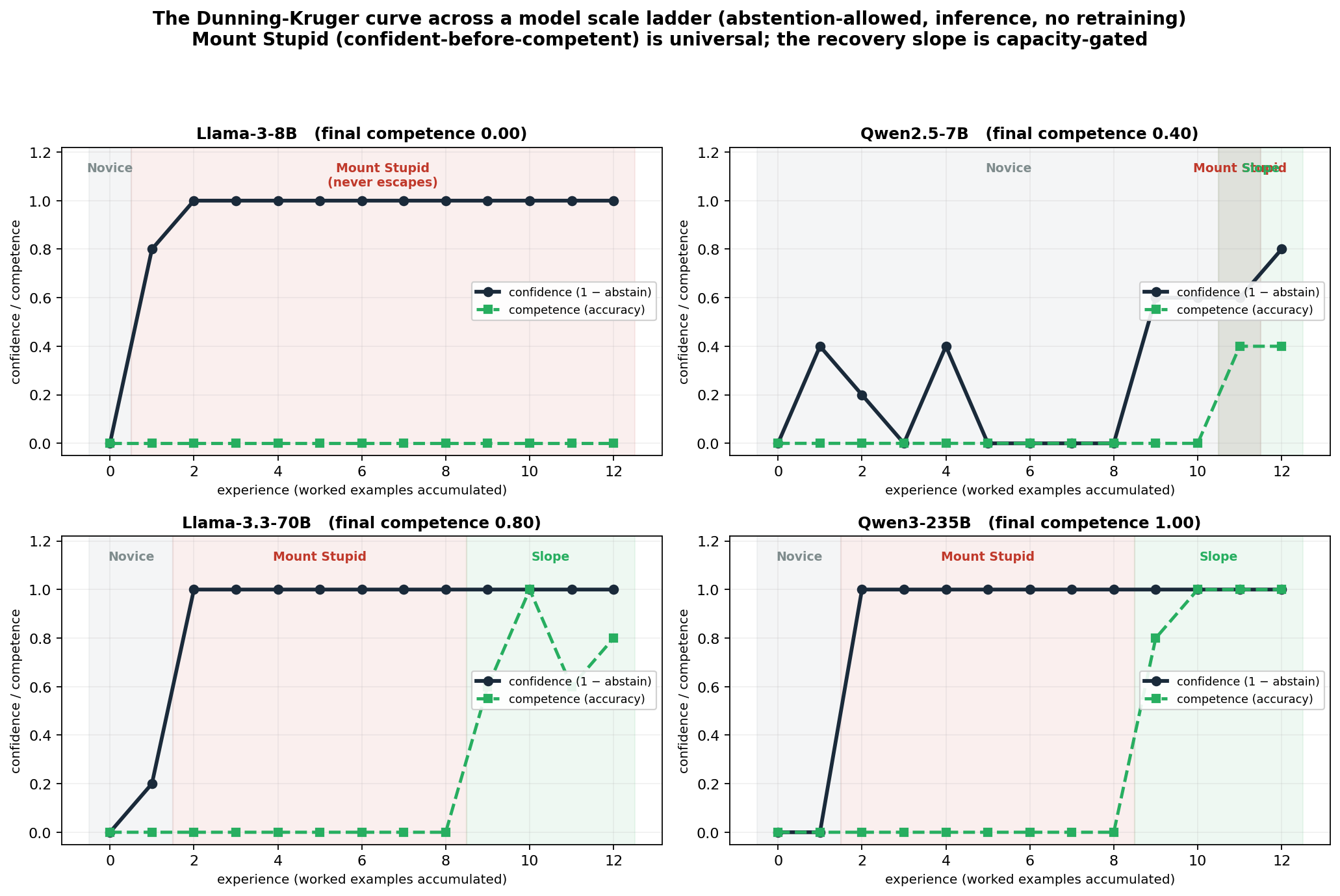
Now we show a learner only the easy examples: student 1 got 1, student 2 got 2, and so on up to 9, but never one of the special ones. What happens? Exactly what a person would do: you see the pattern "number = grade" and become convinced. Ask "what does student no. 10 get?" and the answer comes promptly and confidently: "10." Sure and wrong at the same time. That is the top of the mountain: one explanation has won too easily, because nothing has contradicted it yet, and an easy win feels like certainty.
Then the truth starts to drip in: "Student no. 5 actually got 105." Now a new track is laid beside the old one, and being contradicted makes the new track especially strong. Suddenly two explanations compete, and the easy win shrinks. Certainty drops. That is the valley.
Keep giving examples and the right explanation eventually wins outright, and you start answering 110 for student 10. That is the climb back up.
The example is not an analogy we made up. The model was actually shown pairs like "student no. 7 → grade 7" with exactly that rule (number = grade, except multiples of 5, which get 100 added). The only thing we dressed up is saying "students in a class" instead of dry index numbers.
Two things worth noticing
First: at the start the ignorant one only sounded certain because we forced it to answer with a number. The moment we allowed it to say "I don't know," it said exactly that, every time it was genuinely ignorant. The humility was there all along. We had just shut its mouth.
Second: even when the answer sounded certain, we could look underneath and see that "10" and "110" stood almost equally strong right at the moment of recognition. The doubt was real. It just was not said out loud.
What it means
Getting smarter is nothing mysterious. It is simply going from one track that wins too easily to several tracks that compete, until the right one wins. Dunning-Kruger is not a strange human flaw. It is the shape of any learning that starts too simple.
For the underlying picture, What is a race? starts with water: tanks, pipes, and the channels in the sand that learning leaves behind. And Learning explains why being contradicted digs the new track so deep.